Agent Training
The Science of Q&A Extraction

When you upload a document or crawl a URL, Answerly doesn't just store the text in a big pile. To ensure 100% accuracy, we use a process called Q&A Extraction to turn your raw data into a structured "Source of Truth."
1. Analysis & Breakdown
Our system scans your PDFs, text files, or website pages. It identifies key information, technical specs, pricing, and instructions. It ignores the "noise" (like website navigation or legal footers) and focuses on the high-value content.
You can manage your sources and start the extraction process from the Knowledge tab.
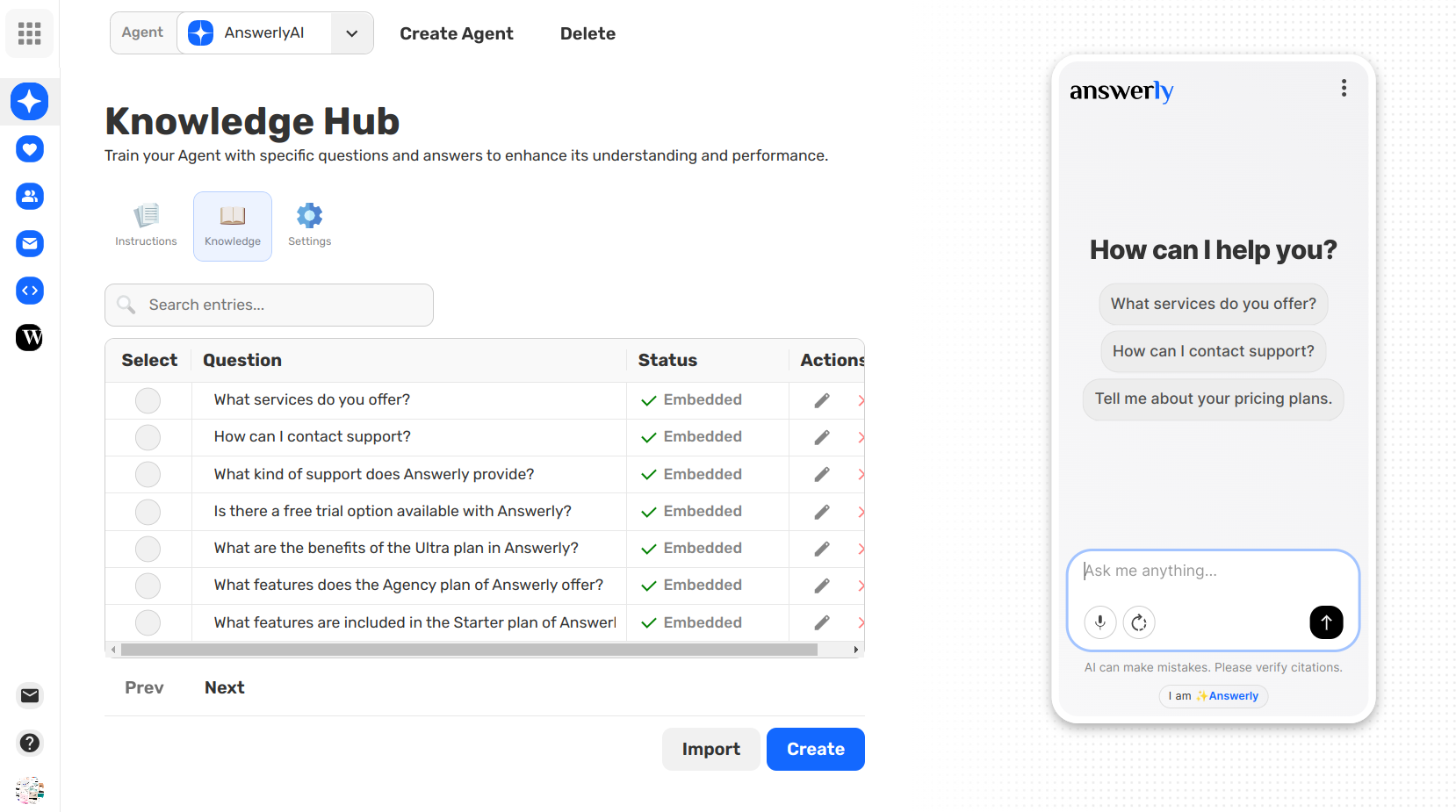
2. Turning Content into Q&As
This is the "Science" part. Answerly transforms your paragraphs into specific Question & Answer pairs.
- The Raw Data: "Our Pro plan costs $29/mo and includes unlimited agents."
- The Extracted Fact 1: Question: How much does the Pro plan cost? / Answer: The Pro plan is $29/mo.
- The Extracted Fact 2: Question: Does the Pro plan have an agent limit? / Answer: No, the Pro plan includes unlimited agents.
3. Verification & Truth
These Q&As are then added to your Training. Because the AI is now looking at a list of confirmed facts rather than a messy document, it can provide instant, pinpoint answers without "hallucinating" or making up details.
If a customer asks something that wasn't turned into a Q&A, the AI knows it doesn't have the answer and won't lie.
What’s Next?
Now that you understand the science behind how your AI learns, the next step is to see how you can manually manage, edit, and audit these facts in your dashboard.